篇首语:本文由编程笔记#小编为大家整理,主要介绍了B站取数服务演进之路相关的知识,希望对你有一定的参考价值。在这篇基于Iceberg的湖仓一体架构在B站的实践我们
篇首语:本文由编程笔记#小编为大家整理,主要介绍了B站取数服务演进之路相关的知识,希望对你有一定的参考价值。
在这篇基于 Iceberg 的湖仓一体架构在 B 站的实践我们介绍了B站基于Iceberg的湖仓一体架构实践,本篇我们将继续介绍B站在取数服务方向的演进之路,这也是湖仓一体架构的实践的重要表现方式。
01
引言

数据平台部作为B站的基础部门,为B站各业务方提供多种数据服务,如BI分析平台,ABTest平台,画像服务,流量分析平台等等,这些服务、平台背后都有海量数据的取数查询需求。伴随着业务的发展,取数服务也面临越来越多的挑战:
需求多、人力紧张,越来越多业务基于数据驱动来做运营,相关的取数需求如:指标查询、UP主、稿件等明细数据的个性化查询需求越来越多,导致在需求响应上,有限的人力跟不上业务发展。
系统架构重复建设:基于Lambda,Kappa的大数据应用架构在B站有一些应用积累,但非平台化,导致在新场景支持上,出现重复建设,增加了维护成本。
性能优化成本高:在满足多种取数场景需求上,数据服务引入多种引擎,比如Elasticsearch、ClickHouse、HBase、MongoDB,这些引擎都需要查询定制优化,增加了研发成本。
基于这些问题的思考,我们在取数服务上经过了2次大的架构升级,不断探索服务化,平台化之路,下面介绍我们在这方面的工作,欢迎大家一起学习交流。
02
演进之路

我们在取数服务的升级道路上,大概分为三个时期:最开始是石器时代,这个时期主要以响应业务需求,技术可复用为主;第二时期是铁器时代,我们开始尝试做一些通用服务来支持基础需求,比如统一出仓,统一查询,降低研发成本;第三时期是工业时代,为了更快的响应业务需求,我们尝试引入湖仓技术来进一步提升取数研发的效率。下面分别介绍。
2.1 石器时代 - 烟囱式开发
取数服务在早期建设时,按照常规方式,我们将过程分为4个阶段:数据模型(数仓建模)、数据存储,查询接口(取数接口),数据产品(业务定制),如下图所示:
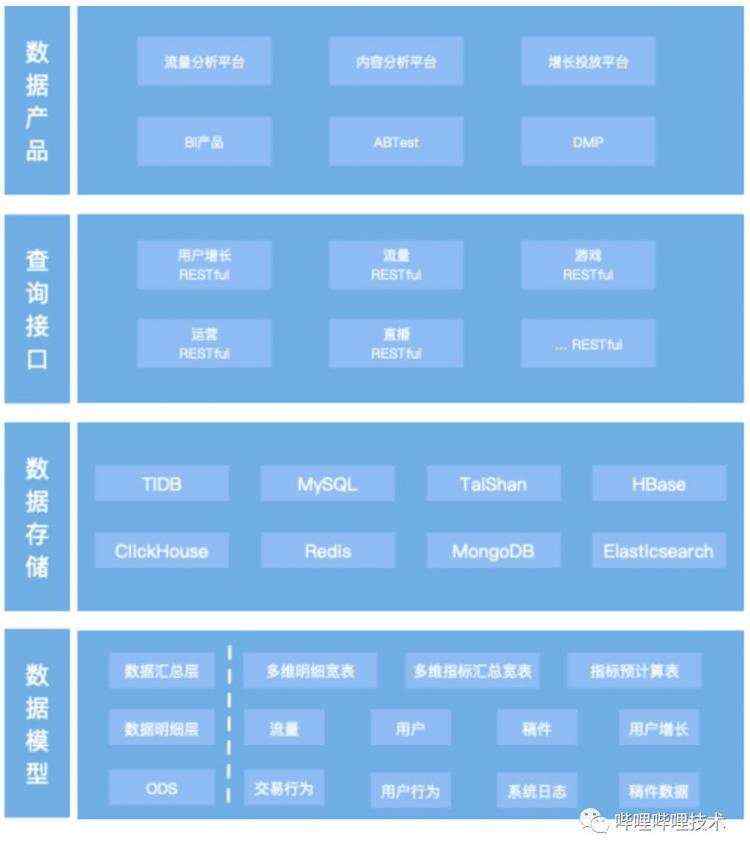
数据模型:数仓建模阶段,按照标准方式,ODS层,DWD层,DWA层来对数据进行分层,分主题建模,通过Hive,Spark对离线数据进行建模,通过Flink进行实时数据建模。最终对业务上透出的以DWD、DWA层数据。
数据存储:根据不同业务场景的数据查询需求,选型不同引擎来支持业务取数,比如指标数据查询,我们会将数据存储到TiDB中;对于明细数据的批量查询,我们会将数据存储到ClickHouse,对于点查数据我们会将数据存储到TaiShan DB(内部的 KV 存储)等等。这些个性化使用,早期基于工程师设计方案选型判断做出决策。
查询接口:基于业务产品的取数需求,定制化研发各种取数HTTP接口。
数据产品:主要支持2大类产品,一类是通用类平台产品,如BI平台,DMP用户画像,ABTest平台,另一类是业务垂类产品,比如B站UP主洞察分析,用户增长指标查询等。
2.1.1 早期面临的挑战
这个模式我们有2个角色来支持业务需求,一个是数仓同学,另一个是应用开发同学,整体研发流程如下:

数仓同学:
在取数需求中承担了主要职责,包括前期的数据探查,确定技术可行性之后,设计数据链路、取数方案,最后实施数据建模、数据出仓,交付可用数据给应用开发同学。
应用开发同学:负责取数接口,产品功能的研发。抽象的取数场景主要有3种:a)指标查询 b)明细数据的批量查询 c)数据点查。
在早期业务量不大的情况下,上述架构和流程能支持业务需求,分工较为明确,但随着业务规模增大,取数需求增多,其带来的问题也逐渐凸显:
重数据模型,数据工作量大,研发周期长,出现人力短板,研发跟不上需求。
技术架构重复建设,比如相同数据不同业务需求会出现重复出仓,相同取数逻辑分业务重复开发,导致维护成本上升。
重复建设也带来了数据口径一致性的问题,排查成本高。
基于上述问题的思考,我们开始将一些标准化的能力升级为统一服务。
2.2 铁器时代 - 统一化服务
这个时期我们重点考虑存储和计算统一。通过将数据的出仓过程标准化,引入数据构建流程,将数据进行统一存储。然后在上面搭建了一个基于SQL DSL的取数引擎,内部代号叫Akuya SQL Engine(ASE)。整体架构如下图所示:

2.2.1 数据构建
数据构建任务是基于Flink实现的流批一体作业,内部代号为Ark。Source对接了kafka和hive hcatalog,分别支持实时数据和离线数据,Sink主要兼容4种引擎来做统一存储:
Elasticsearch:存储指标数据,利用动态列来存储维度信息,支持预计算指标查询。查询响应在毫秒级。
ClickHouse:存储大宽表明细数据,利用ClickHouse的列式存储特性,支持百亿级明细数据查询,查询响应在秒级。
TiDB:存储明细数据,支持亿级数据点查,查询响应在毫秒级。
InfluxDB:存储实时指标数据,查询响应在毫秒级。

上图为数据构建系统的架构,用户通过数据构建平台可视化配置数据出仓任务,平台会根据不同离线、实时数据类型触发相应的Ark任务,并托管在内部的AiFlow(内部自研的机器学习平台)调度平台上。
2.2.2 数据查询
ASE为了兼容不同存储引擎的标准化数据查询,我们引入了SQL语法,参考了Apache Calcite,Tidb Parser项目,考虑到内部服务Go语言为主,我们最终基于TiDB Parser扩展实现了SQL DSL解析,并独立成Service,同时基于Calcite实现自定义JDBC Driver,兼容其他大数据平台。下面以指标数据查询为例,介绍下主要实现思路:


根据维度查询多指标
select dim1, dim2, pv, uv from business.metric where log_date = '20210310'
根据维度分组统计
select dim1, sum(pv) from business.metric where dim1 is not null and dim2 is not null and log_date='20210310' group by dim1
根据年月汇总指标
select month(), sum(pv) from business.metric where dim1 is not null and log_date>&#39;20200101&#39; and log_date<&#61;&#39;20201231&#39; group by month()
单指标年月环比计算
select log_date, pv, year_to_year(pv) from business.metric where dim1 is not null and dim2 is not null and log_date >&#61; "20210301" and log_date <&#61; "20210310"
select log_date, uv, month_to_month(uv) from business.metric where dim1 is not null and dim2 is not null and log_date >&#61; "20210301" and log_date <&#61; "20210310"
month(), year\\_to\\_year(), month\\_to\\_month() 为系统UDF&#xff0c;标准函数
派生指标计算
select CTR(点击pv, 展现pv) from business.metric where dim1 is not null and dim2 is not null and log_date>&#39;20200101&#39; and log_date<&#61;&#39;20201231&#39;
CTR是UDF&#xff0c;支持业务自定义实现
2.2.3 中期面临的挑战
有了数据统一存储和查询之后&#xff0c;我们对应的研发模式上也随之改变如下&#xff1a;

进一步的实践发现&#xff0c;我们依然面临几个突出问题&#xff1a;
数据重复建设&#xff1a;由于存在数据出仓过程&#xff0c;那么离线数据和存储引擎上必然存在重复数据&#xff0c;导致数据管理成本上升。
性能优化成本高&#xff1a;需要考虑为不同的存储引擎做查询优化&#xff0c;定制优化成本高。
开放的工具、服务较少&#xff1a;随着数据应用场景增多&#xff0c;对取数流程引入的功能需求越来越多&#xff0c;如数据安全&#xff0c;数据DQC&#xff0c;数据抽样等等&#xff0c;业务方&#xff08;需求方&#xff09;希望能更多的参与其中&#xff0c;但在这方面平台能力建设不足。
为了能更好的解决这些问题&#xff0c;我们在21年开始尝试引入湖仓一体架构来优化。
2.3 工业时代 - 湖仓一体架构
目前我们在B站探索搭建湖仓架构上的取数服务&#xff0c;主要思路是降低数据出仓成本&#xff0c;在低成本存储架构上&#xff0c;完善数据处理和管理功能。并形成PaaS能力。

我们兼容历史架构&#xff0c;新的湖仓一体平台有几个核心能力&#xff1a;
&#xff08;1&#xff09;基于HDFS的数据湖仓&#xff0c;数据无需出仓&#xff1a;
我们为DB&#xff0c;服务器&#xff0c;消息队列等数据源提供统一的数据接入层&#xff0c;可以快捷将生产环境中的结构化离线数据&#xff0c;实时数据抽取到数据仓库中。实现标准存储。
&#xff08;2&#xff09;打通元数据&#xff0c;湖仓元数据共享&#xff1a;
湖仓基于Iceberg统一建设&#xff0c;通过HCatalog实现湖仓元数据的统一化管理&#xff0c;Hive表和Iceberg表可以无缝切换。
&#xff08;3&#xff09;支持数据索引&#xff0c;提升查询性能&#xff0c;支持数据事务&#xff0c;保障一致性&#xff1a;
直接基于Hive表查询数据较慢&#xff0c;无法直接对接业务取数&#xff0c;但在Iceberg中引入数据索引机制&#xff0c;能大幅度提升取数性能&#xff0c;平均在秒级响应&#xff0c;经过定制调优甚至能到毫秒级&#xff0c;可以满足大部分的取数需求。同时有了大数据上的事务ACID能力&#xff0c;对于一些敏感型业务&#xff0c;可确保并发访问的一致性。感兴趣的同学&#xff0c;可以参考另外一篇文章《B站基于Iceberg的湖仓一体架构实践》。
&#xff08;4&#xff09;开放更多数据处理服务能力&#xff0c;加速数据应用&#xff1a;
有了Iceberg强大的数据查询性能作为后盾&#xff0c;同时数据无须出仓&#xff0c;我们在湖仓上逐步完善数据服务能力&#xff0c;并使之平台化&#xff0c;直接开放给用户使用。比如&#xff1a;
数据索引&#xff1a;我们支持先建表后加索引&#xff0c;所以在取数使用时&#xff0c;可以按需来性能调优&#xff0c;我们将能力平台化&#xff0c;方便用户根据自己需求来优化索引&#xff0c;提升取数体验。
Ad-Hoc&#xff1a;数据探查分析是很高频的一个需求&#xff0c;我们通过对接Trino服务&#xff08;自研的Iceberg查询服务&#xff09;&#xff0c;可以支持交互式分析。
数据ETL&#xff1a;并支持SQL语法读写Hive表和Iceberg表&#xff0c;如&#xff1a;
insert overwrite table iceberg_rta.dm_growth_dwd_rta_action_search_click_deeplink_l_1d_d
select
search_time
, click_time
, request_id
, click_id
, remote_ip
, platform
, app_id
, account_id
, rta_device
, click_device
, start_device
, source_id
from b_dwm.dm_growth_dwd_rta_action_search_click_deeplink_l_1d_d
where log_date&#61;&#39;20220210&#39;
distribute by source_id sort by source_id
2.3.1 现阶段的挑战
在湖仓一体架构上&#xff0c;我们通过完善平台能力&#xff0c;支持多人协同参与研发&#xff0c;提升效率&#xff0c;变成如下&#xff1a;

数仓同学&#xff1a;负责数据接入湖仓&#xff0c;轻度模型建设&#xff0c;降低数据复杂度。
BI同学&#xff1a;通过更多的平台化功能&#xff0c;BI同学也可以介入&#xff0c;根据数据产品需求进行数据探查&#xff0c;并能直接作用在数据产品上。
应用开发同学&#xff1a;通过索引、事务能力&#xff0c;更灵活的实现取数需求&#xff0c;支持更多的应用场景开发。
当前我们在湖仓架构上的应用工具还在完善中&#xff0c;后续会开放更多的数据处理服务方便用户取数。
03
总结展望

湖仓一体架构的引入&#xff0c;让数据处理变的更加高效。我们围绕湖仓架构大胆探索&#xff0c;小心求证。在新老架构上做了较多的融合工作&#xff0c;比如元信息管理&#xff0c;查询服务等工作。通过实践经验来看&#xff0c;湖仓一体能促进更多研发协同&#xff0c;降低用户生成数据、使用数据的门槛。未来&#xff0c;我们将继续提升平台化能力&#xff0c;进一步提升取数体验。








 京公网安备 11010802041100号
京公网安备 11010802041100号